Motivation
Der ADFC-Stormarn e.V. verwendet Klebeetiketten zur Codierung von Fahrrädern.

Auf diesen Etiketten ist ein EIN-Code (Eigentümer-Identifizierungs-Nummer) aufgedruckt, die es der Polizei, den Fundbüros und dem ADFC erlauben, den Eigentümer eines Fahrrads zu ermitteln. Eine über aufgeklebte Etikett angebrachte Plombierfolie schützt dieses vor dem Ablösen.

Dieses Verfahren eignet sich auch für andere Gegenstände, wie Kameras, Fahrrad-Akkus, Kinderwagen, Pferdesättel, etc.
Seit 2024 bietet der ADFC Stormarn auch die Codierung von Fahrrädern an Schulen an. Da hier in kurzer Zeit viele Räder codiert werden müssen, werden die Daten der Schülerinnen im Vorfeld in Excel-Tabellen erfasst. Mit Hilfe der erfassten Daten werden Adressetiketten für Fahrradpässe gedruckt und über einen automatisierten Vorgang die EIN-Codes ermittelt. Die im CSV-Format abgelegten Daten können in die App eingelesen werden und von dort aus direkt an den Etikettendrucker gesendet werden (siehe EIN-Code-Generator: PT-E560BT ansteuern).
Diese Seite beschreibt, die Entwicklung und Funktion einer speziellen Extension für den MIT App Inventor zum Einlesen und aufbereiten von CSV-Dateien (UrsCsvReader).
Inhaltsverzeichnis
Über die App Inventor Erweiterung UrsCsvReader
Über die App Inventor Erweiterung (Extension) UrsCsvReader
Viele Funktionen lassen sich mit den Standardkomponenten des App Inventor entwickeln. Häufig ist die dazu aufzubauende Blockstruktur sehr komplex. Die Formulierung der gleichen Lösung ist, wenn man sie in JAVA formuliert, meist deutlich einfacher und übersichtlicher. Über ein Extension-Programm kann man selbst geschriebenen JAVA-Code in eine App-Inventor-App integrieren.
Die hier beschriebene Extension ist speziell für die Bedürfnisse des Allgemeinen Deutsche Fahrrad-Club (ADFC) zugeschnitten. Dennoch werden hier einige Verfahren aufgezeigt, die auch für andere Anwendungen nützlich sein können.
Die Herausforderungen, die mit dieser Extension gelöst wurden:
- Datenerhalt auch nach Schließen eines Screens
- Auswahl der einzulesenden Datei
- Aufsplitten der eingelesen Textdaten in Zeilen und Spalten
Verwendung
Format der Excel-Tabelle
Die verwendete Excel-Tabelle zur Datenerfassung hat folgenden Aufbau:
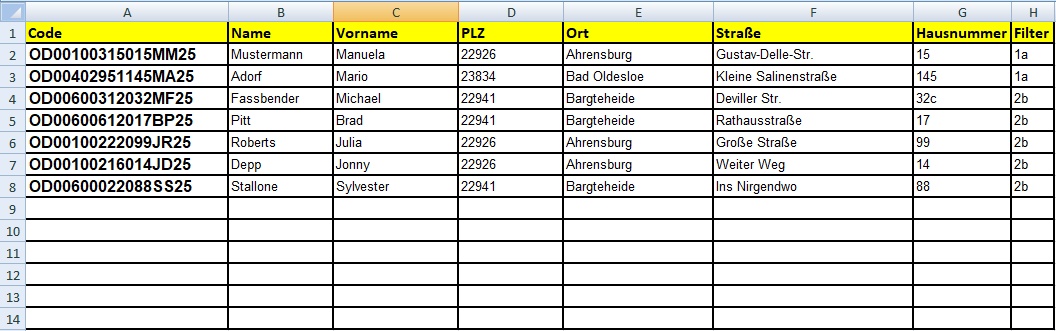
Die Tabelle muss zur Weiterverarbeitung als CSV-Datei gespeichert werden:
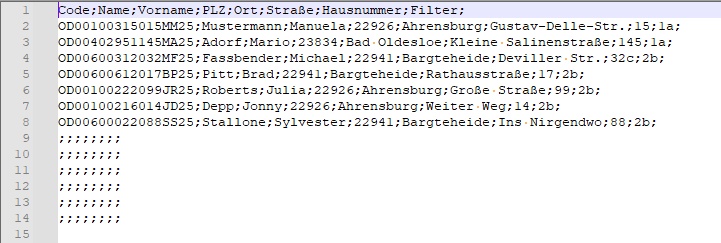
Je nach verwendetem Programm zur Erstellung der CSV-Datei kann es sein, dass die einzelnen Spaltenwerte in Anführungszeichen eingefasst sind. Diese werden von der Einleseroutine entfernt, ebenso Leerzeichen am Beginn und am Ende des Textes.
Übersicht über die Methoden der Extension
Die Methode ReadCSV öffnet einen Dialog zur Auswahl der CSV-Datei in dem vorher beschriebenen Format:
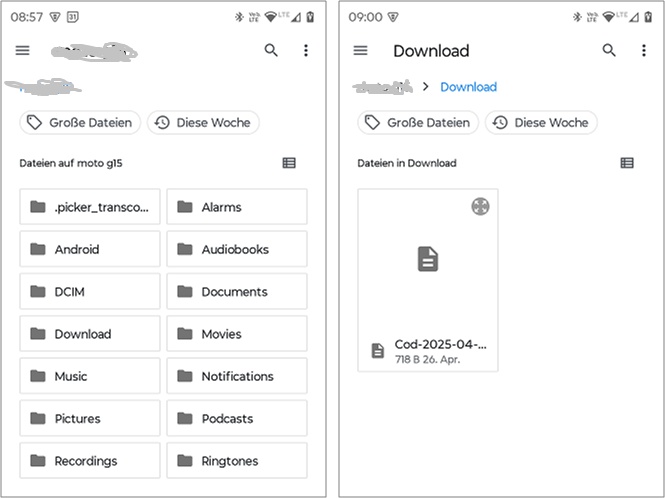 Die
Gestaltung des Dialogs ist abhängig vom benutzten Smartphone kann durchaus anders aussehen.
Die
Gestaltung des Dialogs ist abhängig vom benutzten Smartphone kann durchaus anders aussehen.
Wenn eine Datei ausgewählt wurde, wird sie anschließend sofort eingelesen das Ereignis AfterFileRead ausgelöst. Dies ist das Signal für die App, dass (neue) Daten zur Verfügung stehen. Der Name der ausgewählten Datei kann in lesbarer Form über GetFileName abgerufen werden.
Die Spaltenüberschriften werden nicht ausgewertet. Die Extension verlässt sich darauf, dass die Formatvereinbarung eingehalten wird. Es werden nur die ersten acht Spalten ausgewertet. Weitere Spalten für andere Zwecke, können angehängt werden.
Die Methode GetFilters stellt eine eindeutige sortierte Liste alle Inhalte der Spalte Filter bereit. Diese Werte können genutzt werden, um einen eingeschränkten Datenbereich über die die Methode getFilteredList abzurufen. Der Filterwert * Alle wird automatisch am Anfang der Liste eingefügt.
getFilteredList liefert dann die Liste alle Datensätze, die zu dem angegebenen Filter passen. Die Listenelemente sind vom Type String (Text) und habe den Inhalt <interne ID>;<Anzeigewert>. Anzeigewert ist <Name>, Vorname (<Ort>). Die interne ID kennzeichnet eindeutig ein Datensatz und dient zum Abrufen der spezifischen Spaltenwerte (z.B. GetEinCode).
In der ADFC-App werden die abgerufenen Datensätze in einer ListView-Komponente angezeigt. Um auf die ID der Datensätze zugreifen zu können, wird diese im DetailText der Elemente abgelegt. Damit dieser nicht sichtbar und nicht stört ist, wird die Textgröße auf 1 gesetzt und die Textfarbe gleich der Hintergrundfarbe:
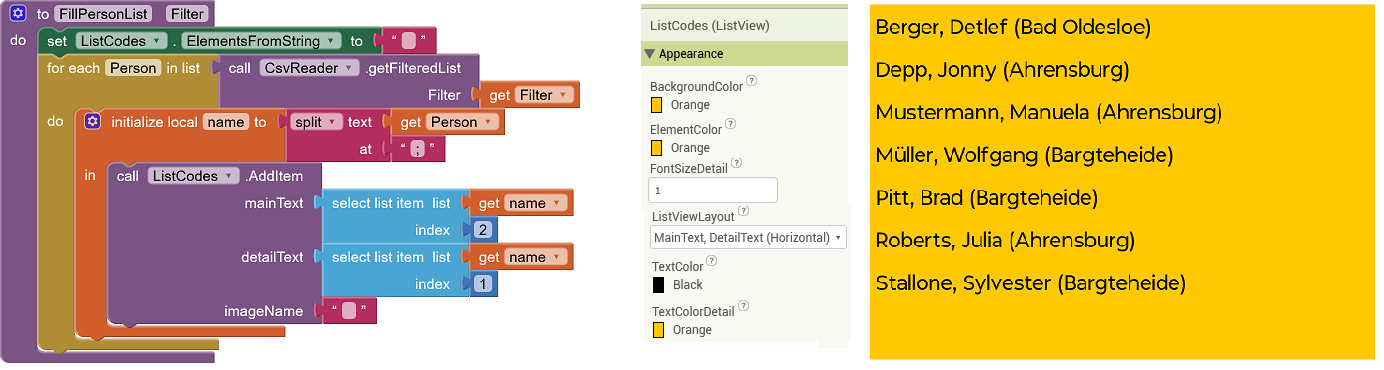
Der Abruf weiterer, zum Eigentümer gehörender Daten erfolgt dann über den selektierten Detail-Text:

In der ADFC-App sieht der Screen dann so aus:

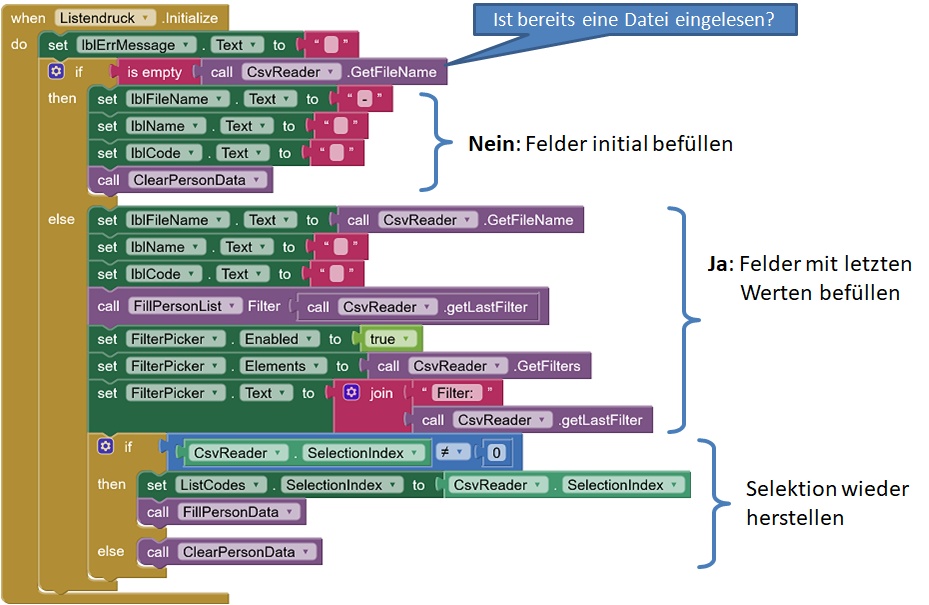
Persistenz
Der Etikettendruck erfolgt in der ADFC-App in einem separatem Screen (abgeleitet von der Android Activity-Klasse), der vom Start-Screen aus geöffnet werden kann. Schließt man den Screen, gehen die bereits bereit gestellten Daten verloren.
Die Extension verwendet deshalb statische Variablen. Eine statische Variable ist nicht an eine Klasse gebunden und nicht an eine Instanz der Klasse. Alle Instanzen der Klasse greifen auf die gleichen Speicherbereiche zu. Diese Variablen werden global abgelegt und nur einmal beim Anlegen der ersten Instanz der Klasse initialisiert. Die Werte dieser Variablen stehen auch dann noch zur Verfügung, wenn die Instanzen vernichtet werden. Damit stehen sie auch nach erneutem Aufruf des Screens wieder zur Verfügung. Die Kehrseite der Medaille ist, dass es keinen Sinn macht, weitere Instanzen der Extension zu verwenden. Sie könnten keine eigenständigen Werte aufnehmen.

Mittels der Eigenschaft SelectionIndex kann der Index der selektierten Person in dem ListView persistiert werden. Damit ist es möglich, den kompletten Screen-Inhalt wieder herzustellen:
Referenz
Eigenschaften
- IsRunningInCompanion
- Gibt zurück, ob die App im Companion ausgeführt wird.
- SelectionIndex
- Speicher für einen Selektionsindex (Integer).
- Version
- Version der Extension.
- VersionSDK
- Der API-Level der aktuell laufenden Android-Instanz.
Funktionen
- GetCity( id)
- Liefert den Ortsname zum Datensatz mit der internen ID id (s. getFilteredList).
- GetEinCode( id)
- Liefert den EIN-Code zum Datensatz mit der internen ID id (s. getFilteredList).
- GetFileName()
- Liefert den Dateinamen der eingelesenen Datei.
- GetFilter( id)
- Liefert den Filter-Wert zum Datensatz mit der internen ID id (s. getFilteredList).
- getFilteredList( Filter)
- Liefert liefert eine Liste der zum Filter gehörende Datensätze. Wenn Filter den Wert
* Alle hat, werden alle Datensätze ausgegeben.
Die Listenelemente sind vom Type String (Text) und habe den Inhalt <interne ID>;<Anzeigewert>. Anzeigewert ist <Name>, Vorname (<Ort>). - GetFilters()
- Liefert liefert eine eindeutige sortierte Liste der Werte in der Spalte Filter der CSV-Datei. Diese Werte können genutzt werden, um einen eingeschränkten Datenbereich über die die Methode getFilteredList abzurufen.
- GetFirstName( id)
- Liefert den Vornamen zum Datensatz mit der internen ID id (s. getFilteredList).
- getLastFilter()
- Liefert den zuletzt benutzen Filerwert (s. getFilteredList).
- GetName( id)
- Liefert den Familiennamen zum Datensatz mit der internen ID id (s. getFilteredList).
- GetStreet( id)
- Liefert Straße und Hausnummer zum Datensatz mit der internen ID id (s. getFilteredList).
- ReadCSV( Title)
- Auswahl und Einlesen einer CSV-Datei mit den EIN-Codes. Title ist der Titel des Dialogs zur Dateiauswahl. Wenn der Vorgang abgeschlossen ist, wird das Ereignis AfterFileRead ausgelöst
Ereignisse
- AfterFileRead()
- Eine (neue) CSV-Datei wurde ausgewählt und eingelesen. Die Daten stehen nun zur Verfügung.
Download
Die Quellen der Extension UrsCsvReader zum Download.
Implementierung
Wie man Erweiterungskomponenten für den MIT App Inventor entwickelt ist hier beschrieben: Extensions entwickeln
Struktur der Extension
| Klasse | Funktion |
|---|---|
| UrsCsvReader | Hauptklasse: Stellt die öffentlichen Eigenschaften und Methoden der Extension bereit. |
| Person | Speichert die (Adress-) Daten eines Eigentümers. |
| Persons | Liste aller eingelesenen Eigentümerdaten. |
Die folgenden Beschreibungen geben eine kurzen Überblick über die wesentlichen Methoden der Klassen.
Klasse Person
Die Klasse nimmt die Daten eines Eigentümers auf:
public class Person {
static int idCounter = 0;
int id;
String code;
String name;
String firstName;
String postCode;
String city;
String street;
String number;
String filter;
String sortString;
String displayString;
Person(String code, String name, String firstName, String postCode, String city, String street, String number,
String filter) {
this.code = code;
this.name = name;
this.firstName = firstName;
this.postCode = postCode;
this.city = city;
this.street = street;
this.number = number;
this.filter = filter;
sortString = name + ";" + firstName + ";" + city + ";" + street + ";" + number;
displayString = name + ", " + firstName + " (" + city + ")";
id = idCounter++;
}
} Neben den Rohdaten wird eine ID als fortlaufende Nummer erzeugt. Das Feld sortString dient zur alphabetischen Sortierung der Eigentümerliste (Klasse Persons) nach Namen. In displayString wird eine Kombination aus Name und Ort abgelegt, die zur Anzeige in dem ListView dient.
Klasse Persons
Die Klasse verwaltet eine Liste von Instanzen der Klasse Person. Das Hinzufügen weiterer Instanzen geschieht wie üblich über die Methode add. Wenn alle Eigentümerdaten hinzugefügt wurden, wird die Liste alphabetisch nach Namen sortiert. Das Feld sortString dient als Sortierkriterium:
void sort() {
Collections.sort(persons, new Comparator<Person>() {
@Override
public int compare(Person lhs, Person rhs) {
return lhs.sortString.compareTo(rhs.sortString);
}
});
}Die Methode getFilters liefert eine eindeutige Liste der Inhalte der Spalte Filter (Spalte H (Nr. 8)) aus der CSV-Datei. Jeder Wert ist nur einmal enthalten. An den Anfang der Liste wird "* Alle" eingefügt.
YailList getFilters() {
List<String> filters = new ArrayList<String>();
for (Person person : persons) {
if (!filters.contains(person.filter))
filters.add(person.filter);
}
Collections.sort(filters);
filters.add(0, "* Alle");
return YailList.makeList(filters);
}Anhand des übergebenen Filterwertes liefert getFilteredList eine Liste aller Eigentümer mit diesem Filterwert, die sich zur Anzeige in einem ListView-Block eignet (s.o.).
YailList getFilteredList(String filter) {
List<String> filtered = new ArrayList<String>();
for (Person person : persons) {
if (filter.equals("* Alle"))
filtered.add("" + person.id + ";" + person.displayString);
else if (person.filter.equals(filter))
filtered.add("" + person.id + ";" + person.displayString);
}
return YailList.makeList(filtered);
}getPerson selektiert eine Instanz der Klasse Person anhand ihres ID-Werts:
Person getPerson(int id) {
if (lastSelectedPerson != null && lastSelectedPerson.id == id)
return lastSelectedPerson;
for (Person person : persons) {
if (person.id == id) {
lastSelectedPerson = person;
return person;
}
}
return null;
}Da i.d.R. direkt hintereinander mehrere Felder der selben Person benötigt werden, wird zur Zugriffsoptimierung die zuletzt selektierte Instanz von Person zwischengespeichert.
Klasse UrsCsvReader
Die Klasse UrsCsvReader ist die Hauptklasse der Extension. Sie dient zum Einlesen einer CSV-Datei, zum Bereitstellen der Daten in Listenform und liefert Daten zu einzelnen eingelesenen Eigentümerdaten.
Datei einlesen
Das Einlesen einer CSV-Datei ist ein relativ aufwändiger Vorgang, da zur Dateiauswahl eine Android-Dienst aufgerufen werden werden muss, der sein Ergebnis asynchron zurück liefert.
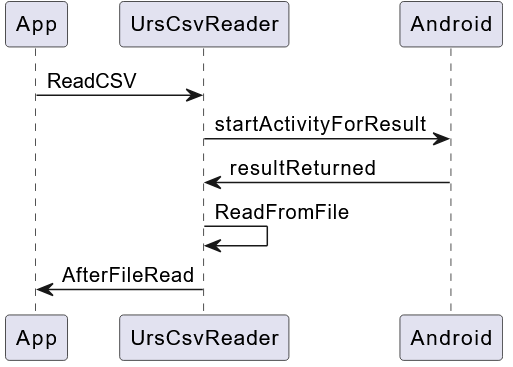
ReadCSV baut zunächst einen Intent auf, mit dem die Dateiauswahl gestartet wird. Die Methode resultReturned empfängt den Pfad zur ausgewählten Datei als Uri. Ein Uri bearbeitet man am besten mit einer Instanz der Klasse ContentResolver. U.a. kann man hierüber einen InputStream abrufen, der zum Einlesen der Daten benutzt werden kann:
InputStream inputStream = contentResolver.openInputStream(Uri.parse(uriString));
Reader reader = new BufferedReader(new InputStreamReader(inputStream, "windows-1252"));Beim Einlesen der Datei muss man bedenken, dass eine unter Windows mit Excel erstellte Datei den Zeichensatz Codepage 1252 benutzt. Ansonsten werden deutsche Umlaute nicht richtig in das unter Android benutzte UTF-8-Format übersetzt.
Die Datei wird zeichenweise in einen StringBuilder eingelesen:
StringBuilder textBuilder = new StringBuilder();
int c = 0;
while ((c = reader.read()) != -1) {
textBuilder.append((char) c);
}Der eingelesene Text wird zunächst in einzelne Zeilen aufgesplittet und dann in die Spalten
String[] lines = textBuilder.toString().split("\r\n");
for (int i = 1; i < lines.length; i++) { // Zeile 0 enthält die Überschriften
if (!lines[i].isEmpty()) {
String[] data = splitString(lines[i]);
...Für das aufspalten der Spalten konnte die Standardfunktion String.Split nicht verwendet werden, da diese leere Elemente nicht in das Ziel-Array aufnimmt. Leere Spalten würden also ignoriert. Die Methode splitString behält auch leere Elemente (modifizierter Code der Java-Funktion):
public String[] splitString(String source) {
char ch = ';';
int off = 0;
int next = 0;
ArrayList<String> list = new ArrayList<>();
while ((next = source.indexOf(ch, off)) != -1) {
list.add(source.substring(off, next));
off = next + 1;
}
// If no match was found, return this
if (off == 0)
return new String[] {};
// Add remaining segment
list.add(source.substring(off, source.length()));
return list.toArray(new String[0]);
}